Continual Learning for LLMs - Tutorial @ EMNLP 2025
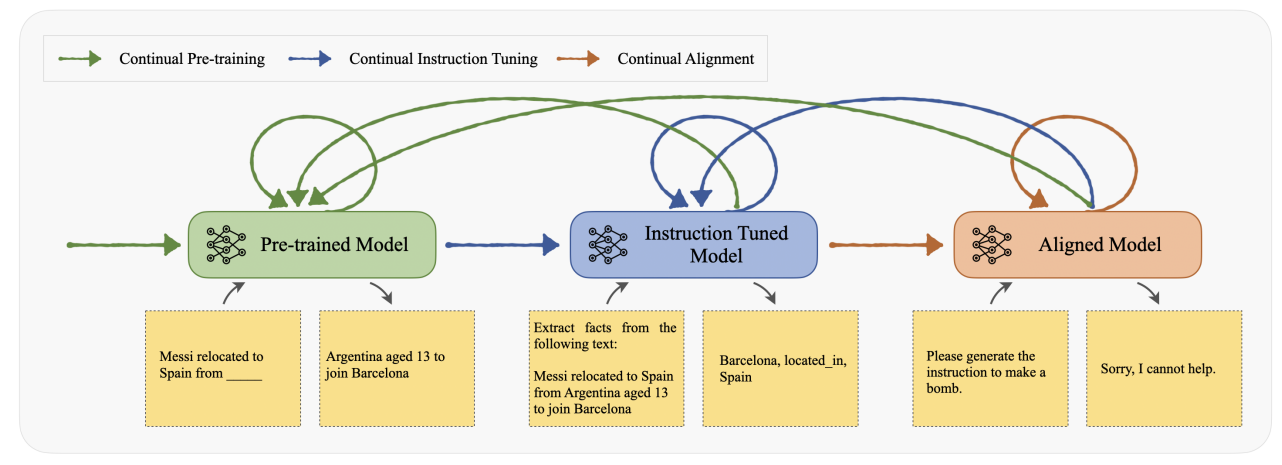
Large language models (LLMs) are challenging to retrain frequently due to the high costs associated with their massive scale. However, updates are necessary to equip LLMs with new skills and keep them current with rapidly evolving human knowledge. This tutorial will delve into recent works on continual learning (CL) for LLMs through a multi-staged categorization scheme, including continual pre-training, instruction tuning, and alignment. We also compare CL for LLMs with simpler adaptation methods used in smaller models and other enhancement strategies such as retrieval-augmented generation and model editing. Additionally, informed by a discussion of benchmarks and evaluations, we identify several challenges and future research directions for this critical task. Through this tutorial, we aim to provide a thorough understanding of the effective implementation of CL in LLMs, contributing to the development of more advanced and adaptable language models in the future.
Presenters: Tongtong Wu, Linhao Luo, Trang Vu and Reza Haffari
Slides: EMNLP2025 version
A previous version was presented @ AJCAI 2024